Speech codecs that convert continuous speech signals into discrete tokens have become essential for speech language models (SLMs). However, existing codecs struggle to balance high-quality reconstruction with semantically rich representations, limiting their effectiveness in both generative and understanding tasks.
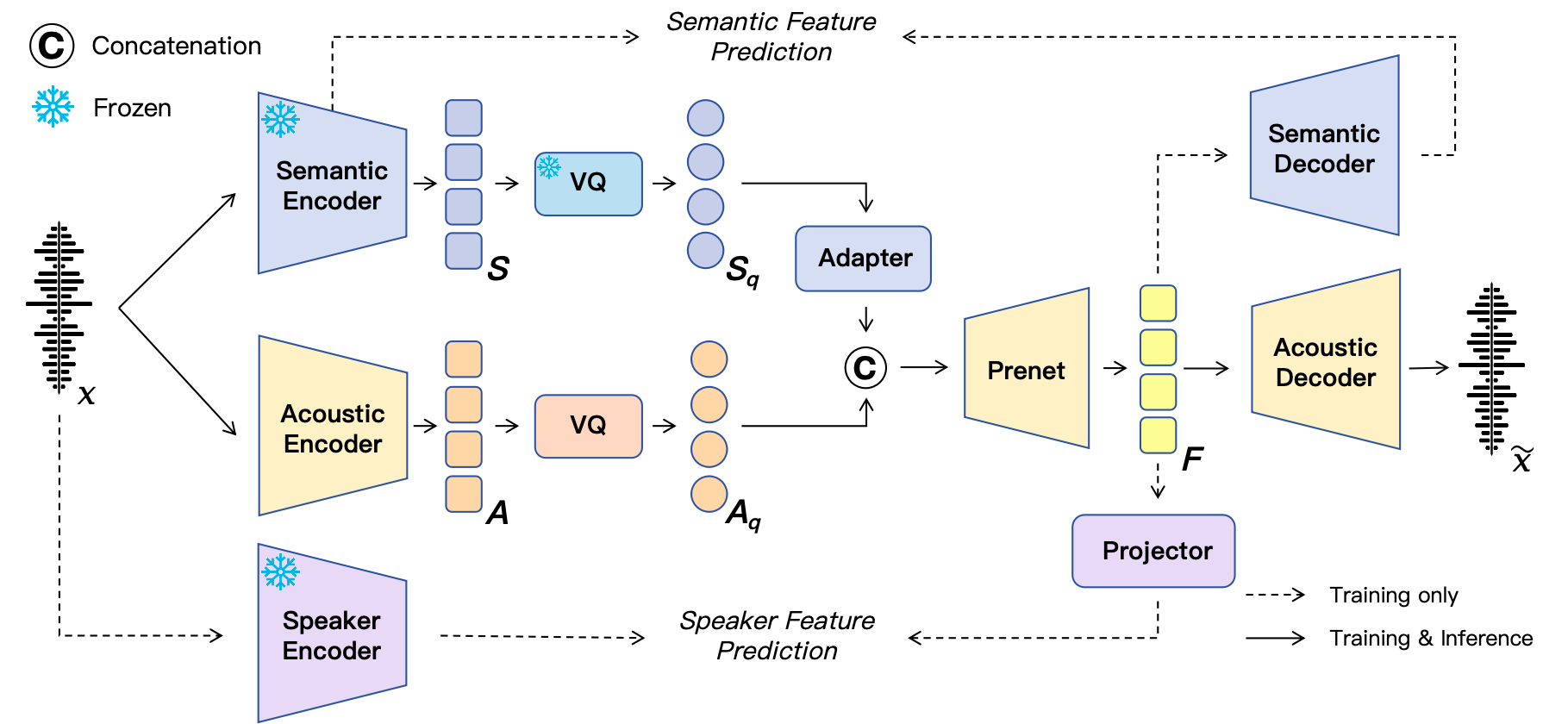
In this work, we propose SAC, a neural speech codec with semantic–acoustic dual-stream quantization. By disentangling semantic and acoustic modeling into two dedicated streams, SAC enables each to be optimized for its respective role. To further enhance timbre modeling, we introduce explicit speaker feature supervision during codec training.
Comprehensive evaluations show that SAC achieves strong reconstruction performance across diverse bitrates under both clean and noisy conditions, with particularly high scores on UTMOS and WER, demonstrating superior perceptual quality and intelligibility. Moreover, SAC substantially outperforms state-of-the-art codecs in semantic representation, achieving a level comparable to that of self-supervised learning (SSL) continuous embeddings. Finally, our analysis of speech disentanglement highlights the effectiveness of the dual-stream design, offering new potential for controllable speech applications.